

Como data lake e data warehouse se diferem?
Data Lake e data warehouse são conceitos fundamentais da gestão estratégica para transformação digital nos negócios. A análise de big data surgiu especificamente na última década para acompanhar as rápidas mudanças de mercado provocadas, entre outros fatores, pelo crescimento das redes sociais, e-commerce e tecnologia móvel.
Com o objetivo de promover operações de negócios competitivas e “à prova do futuro”, as equipes de big data e analytics têm a tarefa de gerenciar e analisar dados corporativos. Eles fazem isso utilizando tecnologias cada vez mais sofisticadas de armazenamento e processamento de dados. As opções mais populares a esse respeito incluem data lakes e warehouses, cada um com uma arquitetura e finalidade exclusivas.
Neste artigo, aprenderemos mais sobre essas soluções enquanto abordamos questões como:
- O que são data lakes e data warehouses;
- Quais são as principais diferenças entre essas estruturas;
- Como cada repositório funciona;
- Como data lakes e data warehouses se encaixam na rotina de business intelligence (BI).
Como resultado desta introdução, você terá os recursos necessários para lançar ou expandir projetos de big data dentro de sua empresa, atendendo aos principais requisitos do seu negócio e maximizando o valor dos dados coletados.
Você está preparado para melhorar seus processos de gerenciamento de dados? Continue lendo e confira!
Classificação e Integração de Dados
Antes de introduzir data warehouses e data lakes, é necessário discutir as categorias de dados e a principal técnica de integração de dados digitais, ETL.
Tipos de Dados
Os dados que agora estão disponíveis online são divididos em três categorias:
Dados Estruturados Dados
São dados que foram formatados de acordo com parâmetros específicos para organização em esquemas relacionados. Um dos formatos mais comuns para dados estruturados é uma tabela, que divide os dados em linhas e colunas com valores pré-determinados.
Exemplos incluem planilhas eletrônicas e bancos de dados de dados (incluindo arquivos Excel, CSV, SQL e JSON, entre outros).
Dados semiestruturais
Como o nome indica são dados com alguma organização interna, mas que não são estruturadas.
Exemplos: artigos da web (HTML, XML, OWL, entre outros).
Dados não estruturados
Esses dados carecem de uma hierarquia interna clara ou estrutura organizacional. Abrange a maioria dos dados online, tornando-se a categoria mais ampla.
Os exemplos incluem documentos de texto (documentos do Word, PDFs), arquivos de mídia (imagens, áudio e vídeo), e-mails, mensagens de texto, dados de redes sociais, dispositivos móveis e Internet das Coisas (IoT).
ETL
ETL significa Extract (Extrair), Transform (Transformar) e Load em inglês (Carregar).
O ETL é o método mais tradicional de integração de dados digitais, com cada termo da sigla de dados designando uma etapa do processo.
ETL: Como funciona o processo?
Extração (E): Os dados são coletados de vários sistemas organizacionais nesta fase e transportados para um local temporário (uma área de preparação), onde são alterados para o mesmo formato para transformação.
Transformação de dados (T): Os dados brutos são limpos e padronizados para atender às necessidades de negócios. Ao final desta fase, os dados estão “limpos”, estruturados e prontos para armazenamento.
Carregamento (L): Os dados processados são enviados para um repositório específico onde são protegidos e disponibilizados para consulta interna.
Desde o final da década de 1970, quando ganhou popularidade, o ETL tem sido usado para estruturar dados para armazenamento em bancos de dados como data warehouses. Vamos aprender mais sobre esses repositórios?
Data Warehouse
Os data warehouses, chamados de “arsenais de dados”, reúnem dados históricos para classificação em grupos semânticos conhecidos como relações. Como resultado, o data warehouse é um banco de dados relacional que contém principalmente dados estruturados.
Data marts, às vezes conhecidos como “mercados de dados”, são subgrupos que distribuem dados de data warehouses e aceleram a recuperação e entrega de dados em períodos designados. Os dados do data warehouse são disponibilizados em forma de leitura mediante solicitação dos analistas de big data e BI.
Os dados do data warehouse são unificados, livres de desvios e inconsistências, e produzem análises altamente precisas que, por sua vez, produzem informações e insights estratégicos. Assim, os data warehouses centralizam os dados corporativos pertinentes, sistematizando-os de forma eficaz e apoiando o desenvolvimento de estratégias de negócios orientadas por dados.
Com planejamento cuidadoso e ETL, os data warehouses aumentam significativamente o valor das decisões organizacionais, pois são estruturas que permitem a otimização prática dos dados armazenados.
Big Data e a revolução dos dados
Desde a década de 1990, o uso comercial e doméstico da internet aumentou, acelerando a geração de dados e o tráfego online. O conceito de big data surgiu como resultado desse fenômeno, que também expôs as limitações dos data warehouses e repositórios similares, como bancos de dados (bancos de dados).
Os gerentes de tecnologia impediram o colapso dos sistemas convencionais de gerenciamento de informações usando dados de volume, velocidade e variedade sem precedentes (os “3 Vs do big data”). A transformação de dados para uso corporativo torna-se uma operação muito cara devido a uma série de fatores, incluindo a necessidade de milhões de gigabytes de armazenamento (de dados que nem sempre eram pertinentes). Por exigir, obviamente, mão de obra qualificada, secundariamente, por consumir cada vez mais tempo de equipes comprometidas.
Como resultado, era um desafio urgente para as empresas tornar o gerenciamento de dados mais eficaz, seguro e financeiramente viável. Os primeiros protótipos de uma solução inovadora surgiram no início dos anos 2000: o data lake.
Data Lake
O que vem à mente quando você pensa em um lago? Talvez a ideia de um grande reservatório natural cuja água pudesse ser filtrada para fornecer seu entorno. Essa fórmula, desenvolvida pelo cofundador do Pentaho, James Dixon, ajuda a entender a ideia de um data lake (também conhecido como “lago” ou repositório de dados).
O data lake é um banco de dados não relacional, ao contrário do data warehouse. Alternativamente, refere-se a um repositório onde os dados “dessembocam” em seu formato original (seja estruturado, semiestruturado ou não estruturado) sem que seja necessária uma estruturação prévia dos dados.
Uma vez derivados de sistemas e aplicativos corporativos, os dados são “puxados” para o data lake durante a fase T do ETL (transformação). Sem esse tratamento, o repositório pode armazenar centenas de petabytes (1 PB é mais de 1.000 terabytes) de enormes volumes de dados de qualquer tipo e escala.
Quais são os benefícios de manter uma estrutura tão forte quanto o data lake? O ato de manter os dados seguros e processá-los conforme a necessidade. Por exemplo, a água do lago pode ser filtrada para encher garrafinhas de 500 ml ou um caminho-pipa. Os dados do data lake, que são em grande parte não estruturados, são mais flexíveis da mesma forma porque não foram encaixados em esquemas pré-definidos.
Além de reduzir os custos de armazenamento e os requisitos de tempo, o data lake permite a automação de processos e a inovação orientada por dados, impulsionando as empresas para uma transformação digital. Os dados podem ser “personalizados” para projetos em todas as áreas, além do desenvolvimento de algoritmos de aprendizado profundo. Eles também podem ser estruturados para colocação em data warehouses onde serão utilizados em análises estratégicas.
A maioria dos cientistas e engenheiros de dados que gerenciam data lakes são responsáveis por projetar a arquitetura, integrá-la ao fluxo geral de dados e gerenciar a enorme riqueza de dados derivados.
Concluindo, trata-se de uma solução que gerencia os dados de forma econômica e dinâmica, alinhando o negócio com as tendências atuais do mercado.
Qual é a melhor opção entre Data Kake e Data Warehouse?
Embora ambos se concentrem no armazenamento e no processamento de dados, existem quatro diferenças principais entre data warehouses e data lakes: conteúdo, função, usuários e tamanho. Confira a comparação abaixo:
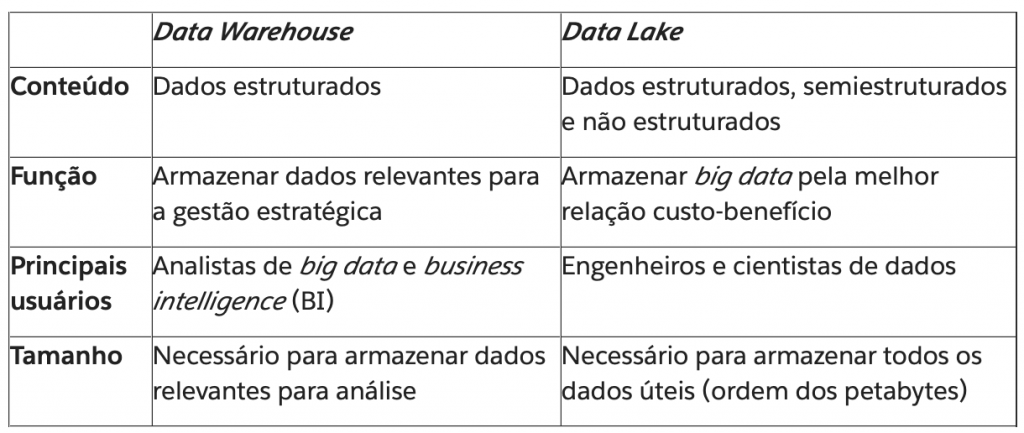
Para escolher a melhor opção para o seu negócio, você deve levar em consideração fatores como a receita da empresa, os objetivos de seus projetos de big data e suas limitações. Qual é sua prioridade atual: gerenciar dados de forma mais eficaz? Obter informações de inteligência de mercado? Ou para fortalecer a área de inovação e soluções digitais?
Como regra, os data lakes são ideais para gerenciar dados não estruturados e os data warehouses são cruciais para análises em larga escala. No entanto, é importante ter em mente que os repositórios não são excluídos. As vantagens de data warehouses e data lakes se combinam quando integram o mesmo fluxo de gerenciamento de dados, incluindo aumento de produtividade, maior assertividade nas análises e melhores relações custo-benefício.
Por fim, outro ponto que precisa ser avaliado é o modelo de armazenamento, que pode ser local (on-premises), baseado em nuvem ou híbrido. A escalabilidade e o baixo custo do armazenamento subterrâneo o tornaram atrativo, pois não requer integração com sistemas locais. Engenheiros de dados e outros especialistas podem orientar você e sua equipe no planejamento da inicialização mais segura e eficaz para o seu negócio.
Conheça a Golden Solutions
A Golden Solutions conta com centenas de clientes atendidos, comercializando licenças de software e desenvolvendo serviços como gestão de nuvem, consultoria e serviços gerenciados, além de um portfólio amplo de soluções verticalizadas com foco em inovação e transformação digital.
Conte com o nosso apoio para implantar toda uma metodologia de Data & Analytics para auxiliar o crescimento do seu negócio.


